
Autotune
ストックにはログインが必要です
Run local LLMs faster and smoother on your device
Artificial Intelligence
Developer Tools
Tech
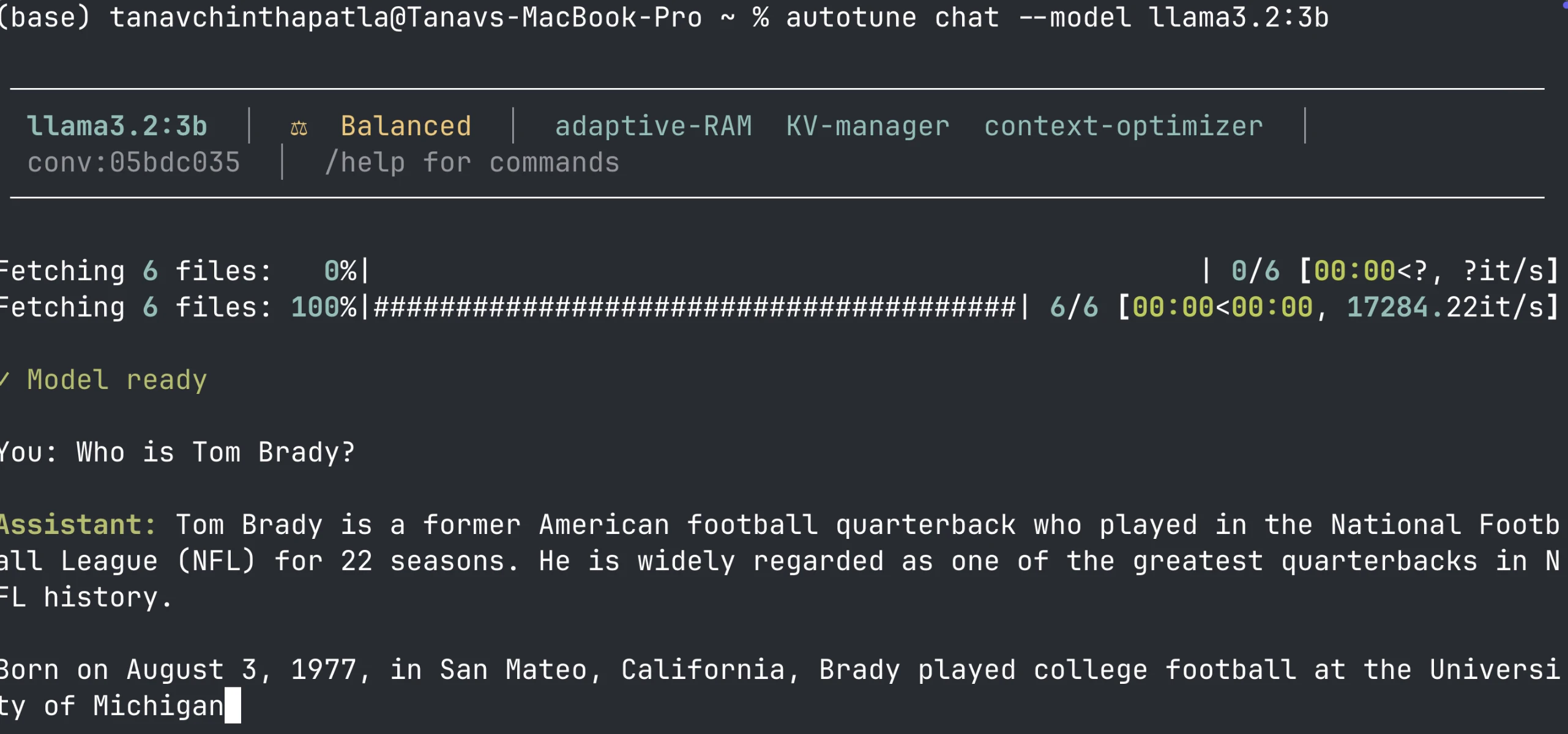
Autotune is an open-source runtime optimizer for local LLMs that reduces KV cache memory, improves first-token latency, and dynamically adapts inference settings to your hardware and workload. It works with Ollama, MLX, and as an API. Results from benchmarks show that Autotune can lower time-to-first-token by 39%, wall time for agentic workflows by 46%, and KV cache memory usage by 67%. Features include an OpenAI-compatible local API, a built-in CLI, RAM management, and model recommendations.
投票数: 15