Corpus
ストックにはログインが必要です
構造化された研究エンジン。信じられないほど高速。オープンソース。
Artificial Intelligence
GitHub
Productivity
Tech
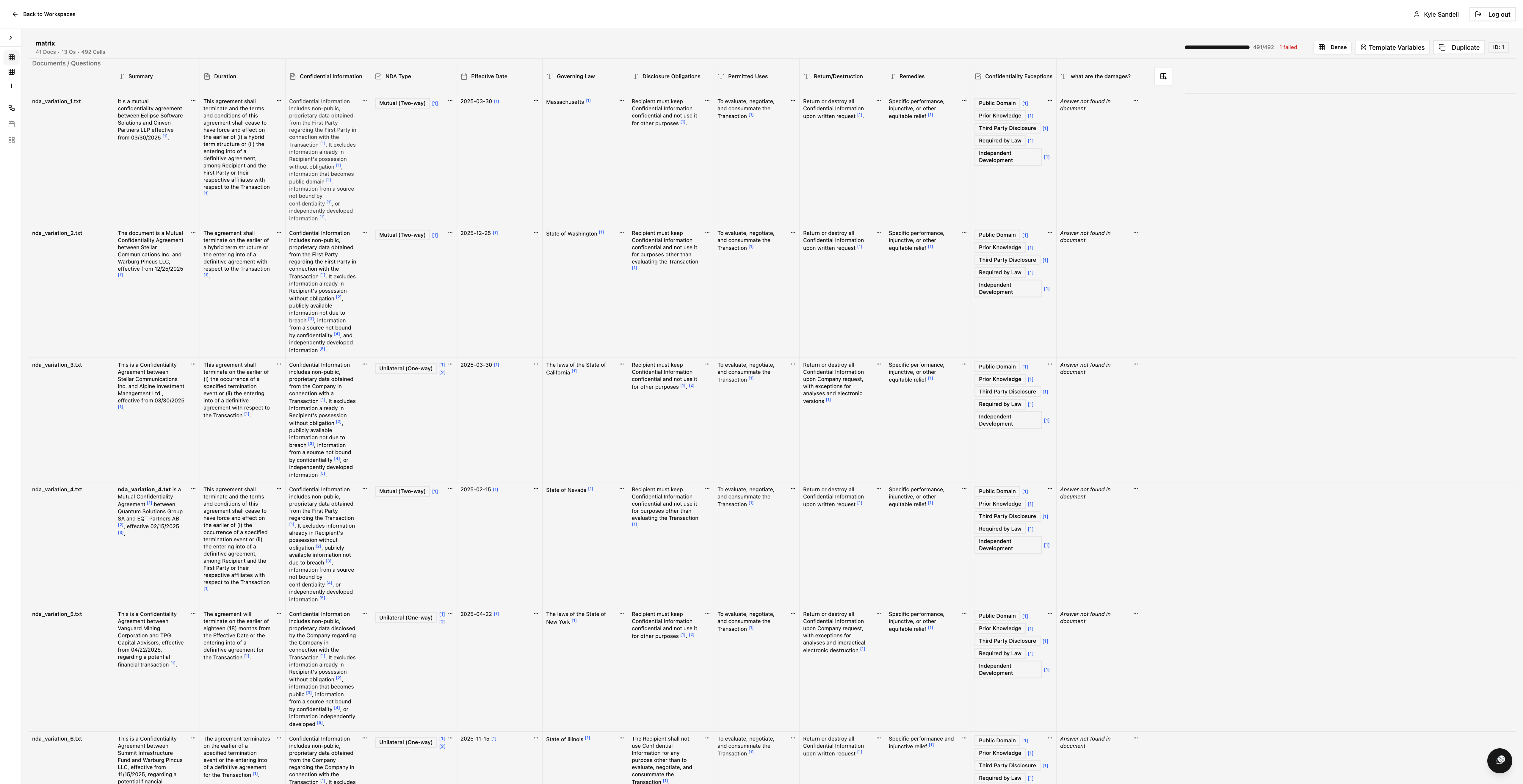
概要
Corpusはオープンソースの文書リサーチエンジン。大量の文書をアップロードし、質問を定義すると、コーパス全体を横断して並列に抽出された回答を構造化データとして返します。PDF/Word/テキスト/音声の文字起こしに対応。アップロード、クエリ、抽出を一度に、未構造データのSQLのように扱える設計。AGPLライセンスで拡張性を重視。
主な使い方
- 複数ファイルをアップロード
- 質問を設定
- 構造化されたスプレッドシートで回答を取得
対象シーン
- 研究、デューデリジェンス、契約審査など、多数の文書から同じ回答を得たい場面に適しています。
投票数: 3