
SemanticGuard
ストックにはログインが必要です
Cuts your LLM API costs by 40-70%. One line of code.
Artificial Intelligence
Developer Tools
API
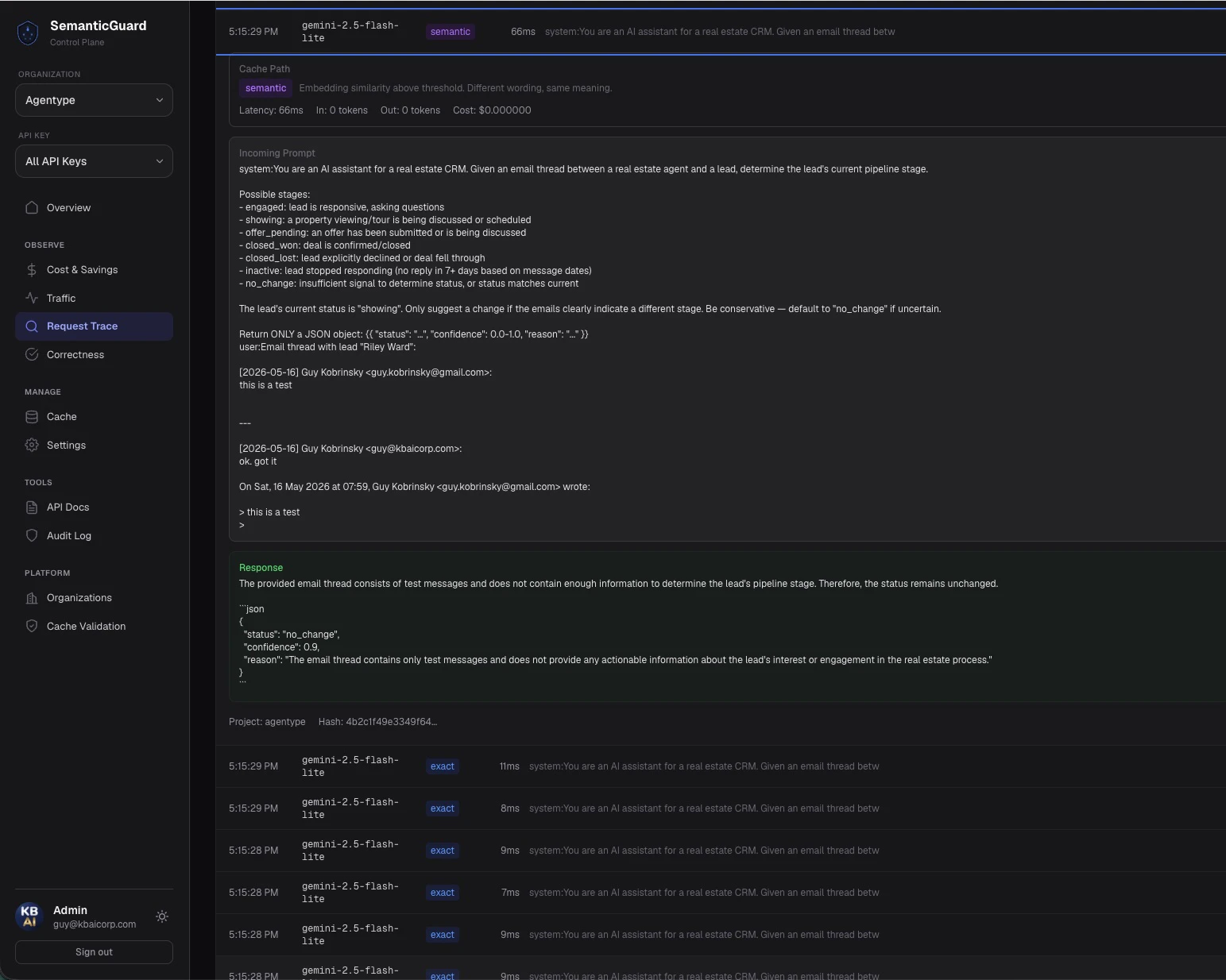
Most LLM calls in production are repeats. Same questions, same prompts, sometimes worded slightly differently. SemanticGuard caches them. Sits between your app and OpenAI/Anthropic/Google, returns cache hits in <50ms, cuts costs 40-70%. One line of code to install. Shadow Mode shows your savings before you flip caching on. Every hit validated by your own AI so you never serve a wrong answer.
投票数: 0