
Sesame
ストックにはログインが必要です
音声の存在感を実現する会話型スピーチモデル
Artificial Intelligence
Open Source
Audio
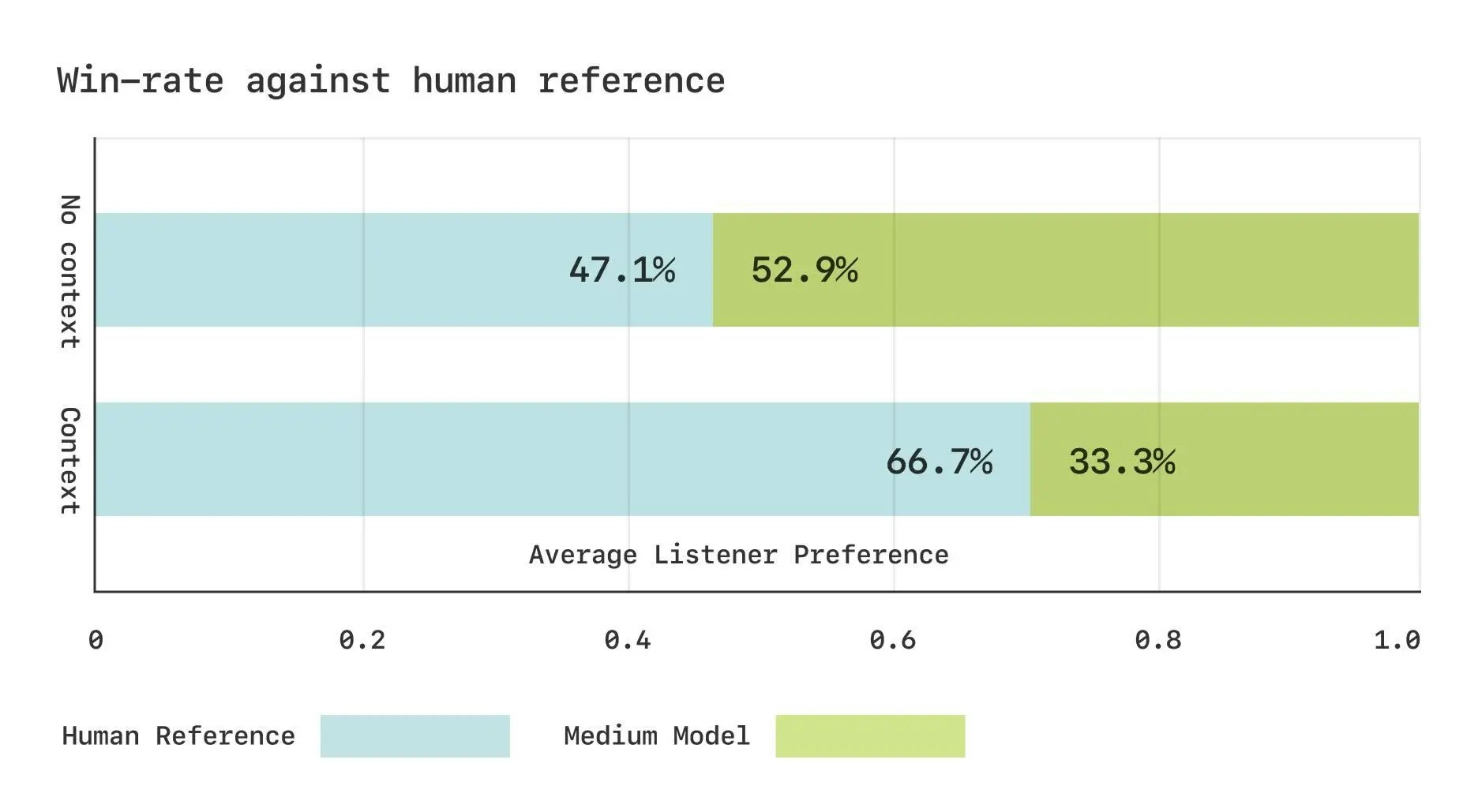
概要
Sesameの会話型スピーチモデル(CSM)は、AIによる音声生成を通じて、自然で魅力的な会話を実現することを目指します。テキスト読み上げを超え、実際の会話のような体験を提供します。
主な特徴
- 感情理解: 会話の感情を察知し、適切に反応。
- 自然なダイナミクス: タイミングやインターバルにこだわったスムーズな会話。
- 状況に応じたトーン: 会話の内容に応じて調整。
- 一貫した人格: 常に明確で一貫性のある応答。
- テキストと音声の理解: 両方の入力形式に対応。
- 効率的な音声生成: 一段階で直接音声を生成。
- オープンソース: Apache 2.0ライセンスのもとでモデルが公開予定。
このモデルはLlamaアーキテクチャに基づいており、ユニークなスプリットトランスフォーマーデザインを採用しているため、従来のメトリックでは測れない自然さを追求しています。デモを通じてその魅力を体感してみてください。
投票数: 171