
TextLayer OCR
ストックにはログインが必要です
スキャン済みPDFを検索可能にしつつ、フォームをそのまま保持する
Artificial Intelligence
Developer Tools
Productivity
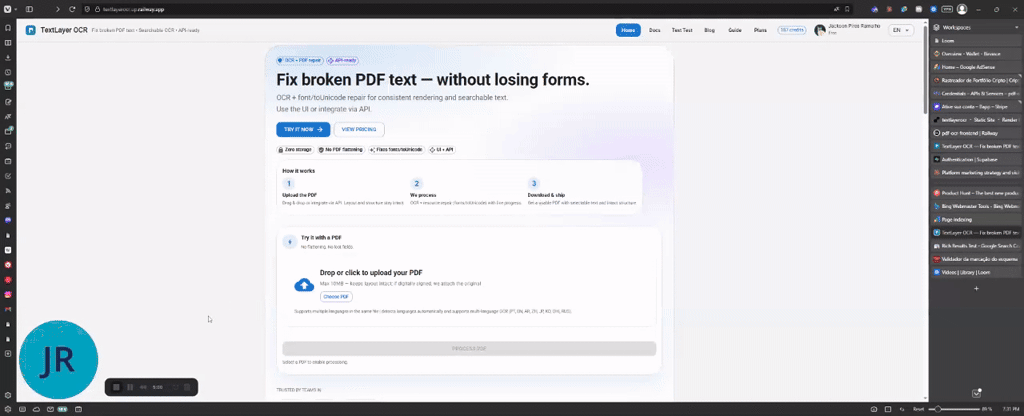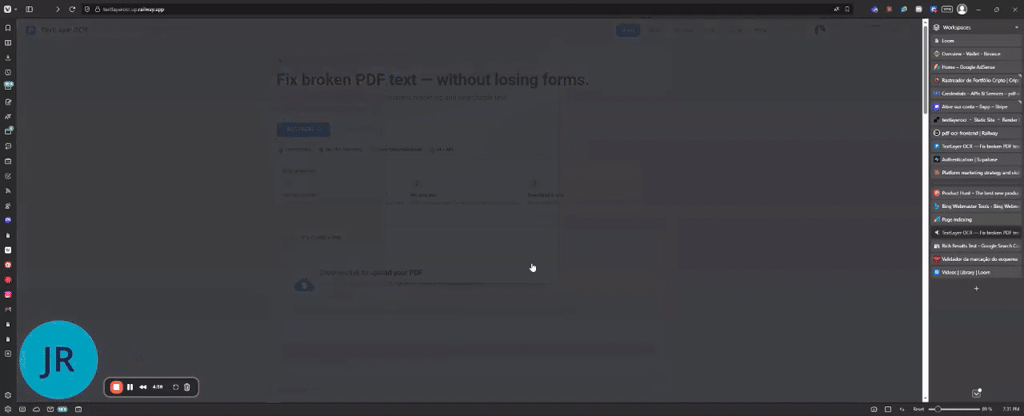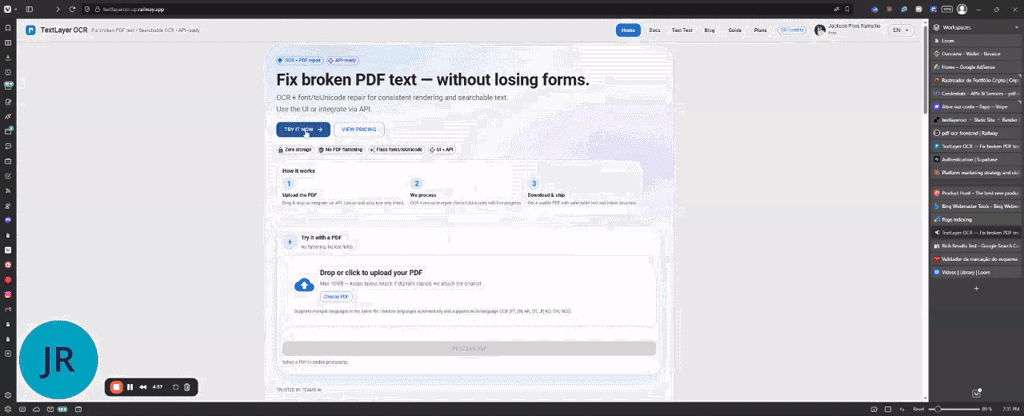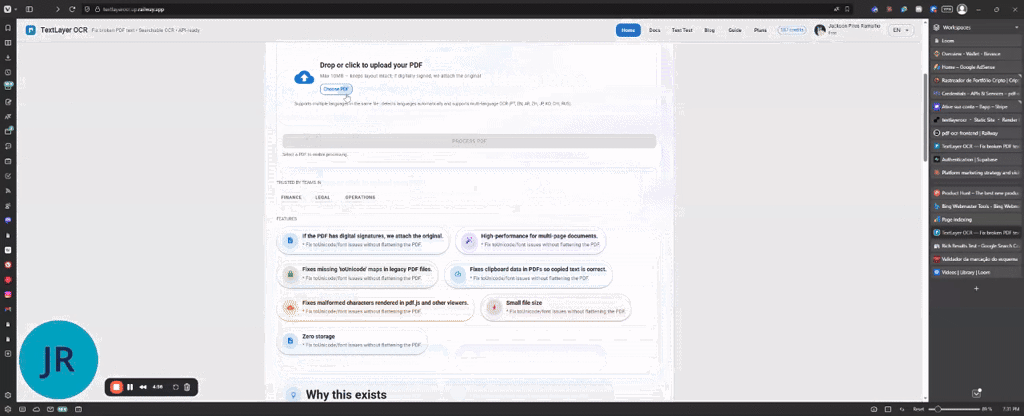
TextLayer OCR は、スキャン済みの PDF を検索可能にするだけでなく、AcroForm のすべてのフィールドとウィジェットを保持します。フォント資源の修復と pdf.js のエンコーディングエラーの修正を行い、元の文書構造を崩さずにOCR を実行します。UI と API の両方で利用でき、自動化を重視した API ファースト設計、無料プランを提供。適用先は法的文書・申込用紙・契約書・編集可能なすべてのスキャン PDF。技術は ASP.NET Core + Tesseract、Railway 上にデプロイ。
投票数: 0